G検定対策!: AIの言語処理 2つのアプローチと「前処理」がわかる学習ノート
『構造』を追う流れと、『統計』で扱うBoW・TF-IDF
1. なぜ「自然言語処理」が必要?
私たち人間は「王様」という言葉を見ればその姿をイメージできますが、コンピュータは「王様」をただの記号としか認識できません。
AIが言葉を扱うには、まず「言葉」をAIが唯一理解できる「数値」に変換する必要があります。
その究極の形が「言葉の地図(分散表現)」です。地図上の「場所(=数値)」で単語の意味を表現し、「王様」と「女王様」は近い場所に配置されます。これにより、「王様 – 男 + 女 = 女王」のような「意味の計算」も可能になります。
しかし、そこにたどり着くには、まず文章をAIが扱えるようにする「下ごししらえ(前処理)」が不可欠です。
2. 下ごしらえ(1):文章の「分解」
日本語のように単語間に区切りがない文章は、まず「単語」に分ける必要があります。
2-1. 形態素解析
- イメージ: 「文法の先生」 👨🏫
- やること: 辞書と文法ルールを使い、文章を「意味を持つ最小単位(形態素)」に分割します。
- 例: 「私は犬が好き」 → 「私 / は / 犬 / が / 好き」
- 特徴: 「名詞」「助詞」など品詞も判別できます。AIが「意味」や「構造」を理解するための必須の作業です。
2-2. N-gram
- イメージ: 「クッキー型」 🍪
- やること: 意味を無視し、指定した文字数(N)で機械的に切り出します。
- 例 (N=2): 「私は犬が好き」 → 「私は / は犬 / 犬が / が好 / 好き」
- 特徴: 「は犬」のように意味不明な区切り方になりますが、辞書が不要で高速です。「この文字の次にこの文字が来やすい」という確率(パターン)を調べるのに使われます(例:スマホの入力予測)。
3. 下ごしらえ(2):「掃除」と「数値化」
AIに学習させる前に、データから「ノイズ」を取り除き、「数値」に変換します。
ここからの流れは、AIの「目的」によって2つに大きく分岐します。
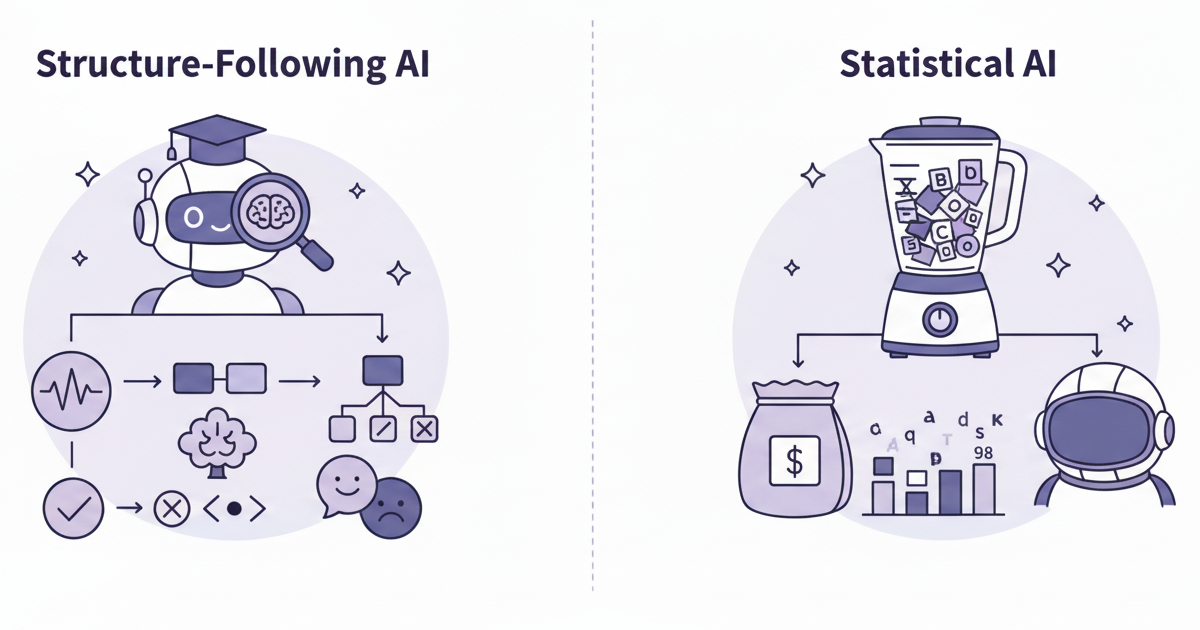
4. アプローチA:「構造」を深く理解するAI(秀才くん 👨🎓)
チャットボットや機械翻訳のように、文章の「意味」や「構造」を人間のように深く理解するためのフローです。
フロー: 形態素解析 → (1)構文解析 → (2)意味解析 → (3)文脈解析
(1) 構文解析(CaboChaなど)
- イメージ: 「文法の先生」 👨🏫
- やること: 単語同士の「かかり受け」(主語・述語など)を明らかにし、文の「骨組み(構造)」を解析します。
- 例: 「私が犬を見た」 → 主語は「私」、目的語は「犬」、述語は「見た」
- ポイント: 「文法的に正しいか」だけをチェックします。
(2) 意味解析
- イメージ: 「常識の先生」 👩🔬
- やること: 構文解析の結果を受け取り、その骨組みが「常識的にありえるか」を判断します。
- 例: 「石がパンを食べる」 → 構文(文法)はOK。しかし、「石は無生物」で「食べる」という動作はできないため、意味的にNGと判断します。
(3) 文脈解析
- イメージ: 「空気を読む先生」 🙅♂️
- やること: その一文だけでは分からない情報を、前後の文脈から補います。
- 照応解析: 「こそあど言葉」が何を指すか特定します。(例:「彼は言った」 → 「彼」=「Aさん」)
- 談話構造解析: 文と文の論理関係(逆接、原因と結果など)を特定します。(例:「雨が降った。だから、中止だ」 → 原因・結果)
5. アプローチB:「統計」でざっくり分類するAI(暗記くん 👨💻)
迷惑メール判定やニュース記事の分類のように、文章の「構造」は無視し、「どんな単語が使われているか」という「統計」でざっくり分類するためのフローです。
フロー: (形態素解析) → (1)クレンジング → (2)Bag-of-Words → (3)TF-IDF
(1) データクレンジング
- やること: 「は」「が」「です」など、文章の意味にあまり関係ない単語(ストップワード)を除去します。料理でいう「皮むき」や「スジ取り」です。
(2) Bag-of-Words (BoW)
- イメージ: 「単語のミキサー」 🌪️
- やること: 文章の「語順」をすべて無視し、単語を「袋(Bag)」にごちゃ混ぜに入れ、「どの単語が何個入っているか」だけを数えます。
- 例: 「犬が私を見た」「私が犬を見た」 → どちらも {犬: 1, 私: 1, 見た: 1} という同じ袋として扱われます。
- ポイント: これ自体が、文章を「単語の個数リスト」という「数値」に変換するシンプルな方法の一つです。
(3) TF-IDF(ティーエフ・アイディーエフ)
- イメージ: 「単語の重要度スコアラー」 💯
- やること: BoWの「単なる個数」を、「その文章の特徴をどれだけ表しているか」という「重要度(重み)」の数値に賢く変換します。
- 計算の考え方:
- TF (Term Frequency): その文章の中で、たくさん出てくる単語は重要かも? → スコア UP
- IDF (Inverse Document Frequency): 他の文章ではめったに出てこない(レアな)単語は重要かも? → スコア UP
- 結果: 「です」のような「どこにでも出る単語」はスコアが低く、「その記事特有の専門用語」はスコアが非常に高くなります。この「スコアのリスト」をAIが学習します。