G検定対策!「ニューラル機械翻訳」がわかる学習ノート
G検定学習ノート:機械翻訳の進化とニューラル機械翻訳
1. 機械翻訳とは?
私たちが普段使う翻訳サイトやアプリのように、「人が翻訳せず、コンピューターが自動で翻訳すること」を指します。この「頭脳」の仕組みは、時代とともに大きく進化してきました。
2. 【第1世代】ルールベース機械翻訳 (RBMT)
- 仕組み(たとえ):
「巨大な辞書」と「巨大な文法ルールブック」を、人間が手作業ですべてプログラムした「ガチガチ頭のロボット」。 - 翻訳の仕方:
- 単語を辞書で置き換える。(例:
cats=猫,dogs=犬) - 文法ルールに従って並び替える。(例: 英語のSVOを日本語のSOVに)
- 単語を辞書で置き換える。(例:
- 弱点:
ルールにない表現(慣用句、スラング、例外)は全く理解できません。
> 例:It's raining cats and dogs.→ 「猫と犬が降っています」
3. 【第2世代】統計的機械翻訳 (SMT)
- 仕組み(たとえ):
人間が作った「完璧な翻訳文のペア(実績データ)」を何億文も読み込んだ「統計の専門家」。 - 翻訳の仕方:
ルールではなく「確率」で翻訳します。「この英語のフレーズは、過去のデータ上、この日本語のフレーズに置き換わる確率が99%」という計算をします。 - 強み:
人間が教えなくても、データ(実績)さえあれば慣用句も正しく訳せるようになりました。
> 例:It's raining cats and dogs.→ (「土砂降り」と訳された実績が多ければ)「土砂降りです」 - 弱点:
- データ依存: 学習データにない口語やスラングは訳せません。
- 意訳が苦手: 翻訳の仕方が人によってバラける「意訳」は、統計上の確率が低くなり、採用されにくいため。
- 限界: あくまで「単語やフレーズの置き換え」であり、「文全体の意味」は理解していません。
4. 【第3世代】ニューラル機械翻訳 (NMT)
- 仕組み(たとえ):
ニューラルネットワーク(AIの脳)を使い、原文の「意味」を丸ごと理解してからゼロから「作文」する「同時通訳者」。 - 強み:
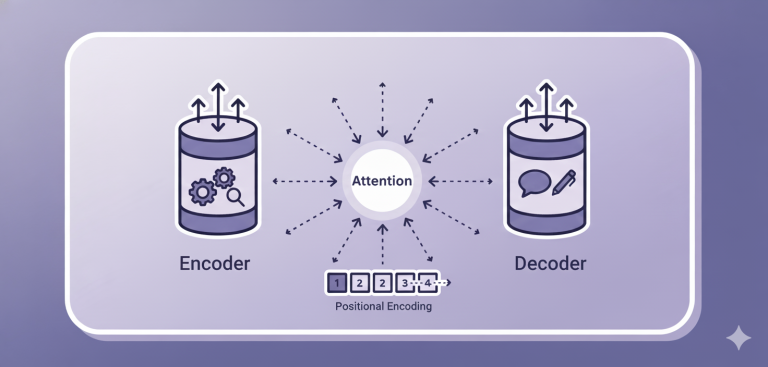
文脈やニュアンスを汲み取った、自然で流暢な「意訳」が劇的に得意になりました。 - 翻訳のプロセス: NMTは2つのAI(エンコーダーとデコーダー)がペアで働きます。
- エンコーダー(耳役)
原文(日本語)を読み込み、単語の意味(分散表現)を理解し、最終的に文全体の「意味のカタマリ(特徴表現)」という数字の暗号に「ぎゅっ」と圧縮します。 - デコーダー(口役)
元の日本語は一切見ず、エンコーダーから渡された「意味のカタマリ(暗号)」だけを見て、ゼロから翻訳文(英語)を1単語ずつ「作文(復元)」していきます。
- エンコーダー(耳役)
5. 【G検定】NMTの最重要キーワード
NMTを理解する上で、特に重要な用語です。
- seq2seq (シークエンス・トゥ・シークエンス)
NMTの基本構造のこと。「エンコーダー(耳役)」と「デコーダー(口役)」のペアの仕組み全体を指します。 - ボトルネック問題
seq2seqの弱点。長い文章になると、「意味のカタマリ」にすべての情報を圧縮しきれず、文の最初の情報がこぼれ落ちてしまう問題。 - アテンション機構 (Attention)
上記の弱点を解決した、NMTの最強の進化。
デコーダー(口役)が翻訳文を1単語ずつ作文するたびに、元の文章(日本語)の「どこに注目(Attention)すべきか」をカンニングできるようにした仕組み。
これにより、長い文章でも正確な翻訳が可能になりました。この「アテンション」の考え方が、現代のAI(ChatGPTなど)の基礎となっています。