G検定対策!「大規模自然言語モデル」がわかる学習ノート
G検定の重要テーマ「大規模自然言語モデル(LLM)」。AIの「脳」がどう動いているのか、その基本を「たとえ話」を交えてわかりやすくまとめました。試験前の振り返り学習にご活用ください。
🤖 1. 大規模自然言語モデル(LLM)って何?
- 昔のAI: 「翻訳専用」や「迷惑メール判定専用」など、一つのことしかできない「缶切り」のようなもの。
- LLM (例: GPT, Gemini): これ一つで「要約、翻訳、質問応答、文章作成」など、言葉に関する様々なタスクをこなせる「十徳ナイフ」のようなもの。これを「汎用的」と呼びます。
🧠 2. 一番大事!「パラメーター」って何?
ここが最大の難関ですが、AIの「勉強」と「本番」で考えるとスッキリします。
- パラメーター(AIの脳みそ)
- AIの「脳の細かな設定値(賢さの本体)」です。
- AIが膨大な勉強(事前学習)をした結果、自動で調整された「何千億個もの数字の集まり」です。
- たとえ: プログラミングの関数
answer = AI_model(question)でいう、AI_modelの中身のロジックそのもの。
- 質問文(入力)
- パラメーターではありません。
- AIに渡す「外部からの情報」です。
- たとえ: AIという賢い脳(パラメーター)に解かせる「テスト問題」や、関数に渡す「引数
question」。
【スケール則】
この「パラメーターの数(=賢さの器)」と、「学習データ量(=教科書の量)」を、両方バランスよく増やすと、AIの性能は予測通りに上がっていくという法則です。GPT-3からGPT-4への進化は、まさにこの法則に従っています。
🎓 3. AIはどうやって賢くなるの?(学習の2ステップ)
AIの学習は「大学」と「会社研修」の2段階に分かれています。
Step 1:事前学習 (Pre-training)
- たとえ: 大学までの一般教養をすべて学ぶこと。
- 目的: インターネット上の膨大な文章を「教師なし学習(穴埋め問題など)」で学び、「言葉のルール」や「世界の常識」をパラメーターに叩き込む。
- 結果: 基礎知識は完璧な「賢い卒業生(=学習済みモデル / 基盤モデル)」が完成する。
Step 2:ファインチューニング (Fine-tuning)
- たとえ: 「賢い卒業生」を、特定の目的のために「会社で追加研修」させること。
- 目的: 会話データや専門知識など、「特化型」の教科書を追加で与え、パラメーターを微調整する。
- 結果: 「ChatGPT(会話のプロ)」や「特定の人物風AI」など、目的に特化したAIが誕生する。
💬 4. AIの「振る舞い」と「倫理観」
- 「鋭い視点です」といった丁寧さや、「倫理的に回答できません」という拒否も、すべてファインチューニング(会社研修)の成果です。
- AIが「人間にとって親切で、安全な」回答をするように、「RLHF(人間のフィードバックによる強化学習)」という「しつけ」技術で厳しく教育されています。
- 課題: AIの倫理観は、AIを作ったベンダー(会社)の「社風(価値観)」が強く反映されるため、どのAIを標準とすべきかという社会的な問題にもつながっています。
⚠️ 5. G検定のための重要キーワード
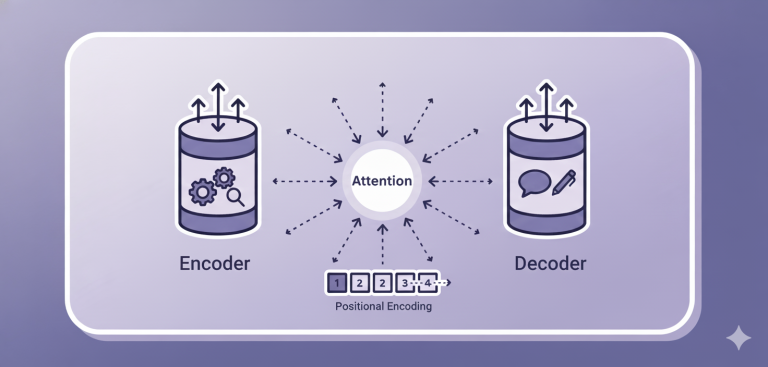
- Transformer (トランスフォーマー):
BERTやGPTの土台となった「革命的な脳の設計図」。 - Attention (アテンション / 注意機構):
Transformerの心臓部。文章中の「どの単語が一番関係が深いか」に注目する仕組み。 - ハルシネーション (幻覚):
AIの最大の課題。学習データにない「事実無根のデタラメ(嘘)」を、自信満々に生成してしまう現象。